Generativní umělá inteligence je skvělá, ale nezapomínejme na její lidské a environmentální náklady.

Během posledních několika měsíců zaznamenala oblast umělé inteligence rychlý růst, přičemž se jedna za druhou objevovala vlna za vlnou nových modelů, jako jsou Dall-E a GPT-4. Každý týden jsou slibovány vzrušující nové modely, produkty a nástroje. Je snadné nechat se unést vlnami humbuku, ale tyto skvělé příležitosti stojí společnost a planetu.
Nevýhody zahrnují environmentální náklady na těžbu vzácných nerostů, lidské náklady na časově náročný proces anotace dat a rostoucí finanční investice potřebné k trénování modelů umělé inteligence, protože obsahují více parametrů.
Pojďme se podívat na inovace, které vedly k nejnovějším generacím těchto modelů a vyhnaly náklady s nimi spojené.
Velké modely
Modely AI se v posledních letech zvětšily a výzkumníci nyní měří jejich velikost ve stovkách miliard parametrů. „Parametry“ jsou vnitřní vztahy používané v modelech k učení vzorů na základě trénovacích dat.
U velkých jazykových modelů (LLM), jako je ChatGPT, jsme díky modelu PaLM od Googlu zvýšili počet parametrů ze 100 milionů v roce 2018 na 500 miliard v roce 2023. Teorie za tímto růstem je, že modely s více parametry by měly mít lepší výkon i v úkolech, na které nebyly původně trénovány, ačkoli tato hypotéza zůstává neprokázaná .
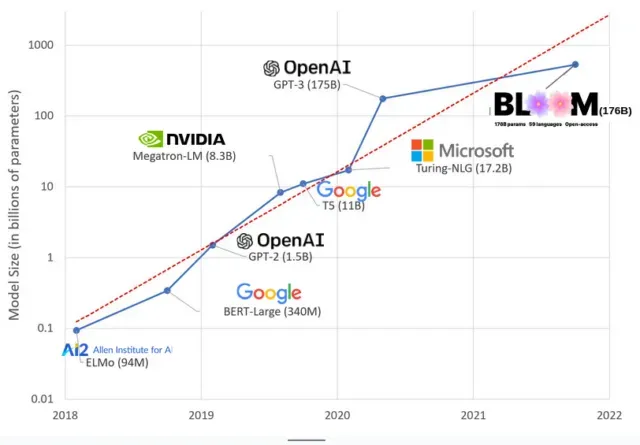
Velké modely se obvykle trénují déle, což znamená, že také vyžadují více GPU, což stojí více peněz, takže je může trénovat jen několik vyvolených organizací. Náklady na výcvik GPT-3, který má 175 miliard parametrů, se odhadují na 4,6 milionu dolarů, což je pro většinu firem a organizací nedostupné. (Stojí za zmínku, že náklady na tréninkové modely jsou v některých případech sníženy , jako například v případě LLaMA, nedávného modelu vyškoleného Meta.)
To vytváří digitální propast v komunitě umělé inteligence mezi těmi, kteří mohou učit nejmodernější LLM (většinou velké technologické společnosti a bohaté instituce na globálním severu) a těmi, kteří to neumí (neziskové, start-upy). a každý, kdo nemá přístup k superpočítači). nebo miliony v cloudových kreditech). Vybudování a nasazení těchto gigantů vyžaduje spoustu planetárních zdrojů: vzácné kovy k výrobě GPU, vodu k chlazení obrovských datových center, energii k udržení těchto datových center v provozu 24 hodin denně, 7 dní v týdnu v planetárním měřítku… to vše je často přehlíženo ve prospěch soustředění Pozornost. o budoucím potenciálu výsledných modelů.
planetární vlivy
Studie profesorky Emmy Strubell z Carnegie Mellon University o uhlíkové stopě školení LLM zjistila, že trénink modelu z roku 2019 s názvem BERT, který má pouze 213 milionů parametrů, vypouští 280 metrických tun uhlíkových emisí, což je zhruba ekvivalent pěti automobilů. život. Od té doby se modely rozrostly a vybavení se zefektivnilo, takže kde jsme teď?
V nedávné vědecké práci, kterou jsem napsal, abych studoval uhlíkové emise způsobené školením BLOOM, jazykovým modelem se 176 miliardami parametrů, jsme porovnávali spotřebu energie a následné uhlíkové emise několika LLM, které všechny vyšly v posledních několika letech. Účelem srovnání bylo získat představu o rozsahu emisí LLM různých velikostí a o tom, co je ovlivňuje.
Napsat komentář