Twitter veröffentlicht Code, der angeblich bestimmt, welche Tweets Menschen sehen und warum.
Twitter löste eines der vielen Versprechen von CEO Elon Musk ein, indem es am Freitagnachmittag den angeblichen Code für seinen Tweet-Empfehlungsalgorithmus auf GitHub veröffentlichte .
Der unter der GNU Affero v3.0 General Public License veröffentlichte Code enthält zahlreiche Details darüber, welche Faktoren dafür sorgen, dass ein Tweet mehr oder weniger wahrscheinlich in der Chronik eines Benutzers erscheint.
In einem Blog-Beitrag zur Veröffentlichung des Codes stellt das Twitter-Entwicklerteam (ohne spezifische Bildunterschrift) fest, dass das System zur Bestimmung der „beliebtesten Tweets, die am Ende für Sie auf der Timeline Ihres Geräts angezeigt werden“ viele miteinander verbundene Dienste und Jobs umfasst. Jedes Mal, wenn der Twitter-Startbildschirm aktualisiert wird, ruft Twitter „die besten 1.500 Tweets aus Hunderten von Millionen“ ab, heißt es in dem Beitrag.
Die größte Quelle dieser Tweets sind „Online-Quellen“ oder Benutzer, denen jemand folgt. Die Top-Tweets aus diesem Stapel werden nach der Wahrscheinlichkeit geordnet, dass ein Benutzer mit dem Autor dieses Tweets interagiert. desto wahrscheinlicher ist es, dass ihre Tweets in For You erscheinen. Bei „Offline-Quellen“, denen der Nutzer nicht folgt, berücksichtigt Twitter nach eigenen Angaben Tweets, die die Aufmerksamkeit der Personen erregen, denen der Nutzer folgt, und Tweets, die von denen geliked werden, die ähnliche Tweets mögen wie der Nutzer.
Wer sich den Code angeschaut hat, dem sind bereits Überlegungen aufgefallen, die noch viele weitere Fragen aufwerfen. Viele haben sie natürlich auf Twitter selbst gepostet.
Twitter hat gerade den Quellcode des „Algorithmus“ veröffentlicht.
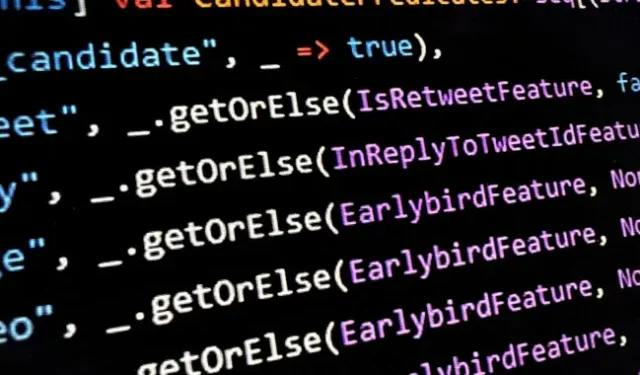
Oh, was ist das für eine Datei? Prädikate für Tweets auf der Home-Timeline?
Oh, was ist das für ein zweites Bild? pic.twitter.com/UE3dU8e3Os
Olafur Vaage, leitender Software-Ingenieur beim norwegischen Software-Beratungsdienst TurtleSec, bemerkte, dass in „ HomeTweetTypePredicates.scala “ einige der möglichen Überlegungen, für die ein Tweet ein Kandidat für den Abschnitt „Für Sie“ sein könnte, wie folgt sind:
-
author_is_elon -
author_is_power_user -
author_is_democrat -
author_is_republican
An anderer Stelle im Code stellt ein angeblich von einem Twitter-Ingenieur hinterlassener Codekommentar klar , dass diese Identifikationswerte „ausschließlich zum Sammeln von Metriken verwendet“ werden. Der Kommentar geht so:
Diese Autoren-ID-Listen werden ausschließlich zur Erfassung von Metriken verwendet. Wir verfolgen, wie oft wir die Tweets dieser Autoren bereitstellen und wie oft ihre Tweets die Benutzer beeindrucken. Dies hilft uns, auf unserer A/B-Experimentierplattform zu bestätigen, dass wir keine Änderungen einreichen, die sich negativ auf eine Gruppe gegenüber anderen auswirken.
Die Namen der betreffenden Objekte, wie „DDGStatsDemocratsFeature“ oder „DDGStatsElonFeature“, scheinen diese Interpretation zu stützen, aber dies kann mit dem verfügbaren Code möglicherweise nicht bestätigt werden. Interessant ist jedoch, dass Twitter diese Variablen überprüft und korreliert. Während der Audiositzung von Twitter Spaces stellte ein Twitter-Ingenieur fest, dass die für die Kennzahlen verwendeten Bezeichnungen Demokraten und Republikaner waren. Musk, der behauptete, er wisse bis heute nichts von den Etiketten, meinte, sie sollten nicht dort sein.
Weitere Faktoren, die im Zusammenhang mit dem Tweet berücksichtigt werden, sind unter anderem, ob er weniger als 30 Minuten alt ist, ob er Bilder enthält und ob es sich um einen „Power-User“ handelt, was laut manchen ein „veraltetes“ verifiziertes Konto bedeutet .
Heutzutage werden die meisten Empfehlungsalgorithmen Open Source sein. Der Rest wird folgen.
Der Härtetest besteht darin, dass unabhängige Dritte in der Lage sein müssen, mit angemessener Genauigkeit zu bestimmen, was den Benutzern voraussichtlich angezeigt wird.
Zweifellos wird es viele unangenehme Momente geben … https://t.co/41U4oexIev
Musk twitterte zusammen mit einem Unternehmensblogbeitrag über den Empfehlungsalgorithmus und argumentierte, dass es einen „Bärtest“ geben würde, wenn „unabhängige Dritte“ „mit angemessener Genauigkeit bestimmen könnten, was den Benutzern wahrscheinlich angezeigt wird“.
Die Veröffentlichung des Algorithmuscodes durch Twitter erfolgt nur wenige Tage, nachdem der umfassendere Quellcode des sozialen Netzwerks auf GitHub entdeckt wurde, der laut The New York Times möglicherweise monatelang dort liegen bleibt . Twitter erhielt daraufhin eine Vorladung, mit der GitHub gezwungen wurde, Informationen über das GitHub-Poster preiszugeben.
In einem Bericht von Platformer Anfang dieser Woche hieß es, dass Twitter eine geheime Liste mit 35 Top-Twitter-Nutzern verwendet habe, darunter Präsident Biden, LeBron James, Ben Shapiro und Musk. Beweise für die Umsetzung dieser Liste, die Berichten zufolge teilweise auf Musks Unzufriedenheit mit seinem eigenen Engagement zurückzuführen ist, müssen bisher in einer auf Twitter veröffentlichten Codebasis gefunden werden.
Konkret kommt der Code nur wenige Stunden bevor „verifizierte Legacy“-Benutzer – diejenigen, die vor dem Kauf des Dienstes durch Musk ein blaues Häkchen hatten, um Authentizität oder Bekanntheit anzuzeigen – zugunsten bezahlter Twitter-Blue-Abonnenten veraltet sein werden. Während einige Benutzer, die mit Regierungen und großen Organisationen in Verbindung stehen, möglicherweise andersfarbige Häkchen beantragen , erhalten Twitter Blue-Abonnenten, die nur 8 US-Dollar pro Monat zahlen , unter anderem eine „Prioritätsbewertung in Gesprächen“ .
Alle diese Änderungen finden am 1. April, dem Aprilscherz, statt.


Schreibe einen Kommentar