Twitter publica un código que, según afirma, determina qué tuits ve la gente y por qué.
Twitter cumplió una de las muchas promesas del CEO Elon Musk al publicar el viernes por la tarde lo que afirma es el código para su algoritmo de recomendación de tweets en GitHub .
El código, publicado bajo la Licencia Pública General GNU Affero v3.0 , contiene numerosos detalles sobre los factores que hacen que un tuit sea más o menos probable que aparezca en la línea de tiempo de un usuario.
En una publicación de blog que acompaña al lanzamiento del código , el equipo de ingeniería de Twitter (sin un título específico) señala que el sistema para determinar cuáles son «los tweets más populares que terminan apareciendo en la línea de tiempo de su dispositivo» «comprende muchos servicios y trabajos interconectados». Cada vez que se actualiza la pantalla de inicio de Twitter, Twitter extrae «los 1500 tweets principales de cientos de millones», dice la publicación.
La mayor fuente de estos tweets son las «fuentes en línea» o los usuarios que están siendo seguidos por alguien. Los mejores tweets de esta pila se clasifican según la probabilidad de que un usuario interactúe con el autor de ese tweet; más probable es que sus tweets aparezcan en For You. Para las «fuentes fuera de línea» no seguidas por el usuario, Twitter dice que considera los tweets que llaman la atención de las personas que el usuario sigue y los tweets que les gustan a aquellos a quienes les gustan los tweets similares al usuario.
Aquellos que han mirado el código ya han notado consideraciones que plantean muchas más preguntas. Muchos los publicaron, por supuesto, en el mismo Twitter.
Twitter acaba de publicar el código fuente del “algoritmo”.
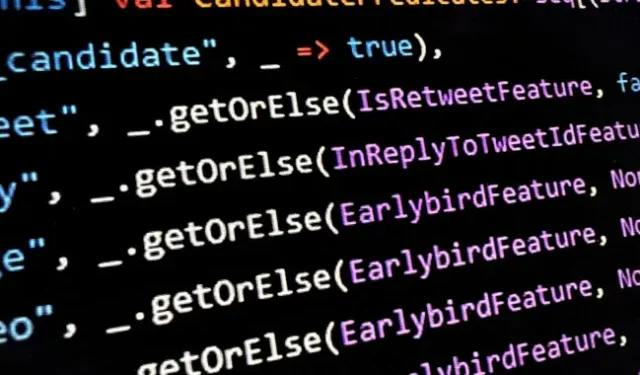
Oh, ¿qué es este archivo? ¿Predicados para tweets en la línea de tiempo de inicio?
Oh, ¿qué es esa segunda foto? pic.twitter.com/UE3dU8e3Os
Olafur Vaage, ingeniero de software sénior del servicio de consultoría de software noruego TurtleSec, señaló que dentro de » HomeTweetTypePredicates.scala » algunas de las posibles consideraciones por las cuales un tweet podría ser candidato para la sección «Para ti» son las siguientes:
-
author_is_elon -
author_is_power_user -
author_is_democrat -
author_is_republican
En otra parte del código, un comentario de código supuestamente dejado por un ingeniero de Twitter aclara que estos valores de identificación se «utilizan únicamente para recopilar métricas». El comentario dice así:
Estas listas de ID de autor se utilizan únicamente para recopilar métricas. Realizamos un seguimiento de la frecuencia con la que publicamos los tweets de estos autores y la frecuencia con la que sus tweets impresionan a los usuarios. Esto nos ayuda a confirmar en nuestra plataforma de experimentación A/B que no estamos enviando cambios que impacten negativamente a un grupo sobre otros.
Los nombres de los objetos en cuestión, como «DDGStatsDemocratsFeature» o «DDGStatsElonFeature» parecen respaldar esta interpretación, pero es posible que no sea posible confirmarlo con el código disponible. Sin embargo, es interesante que Twitter verifique y correlacione estas variables. Durante la sesión de audio de Twitter Spaces, un ingeniero de Twitter señaló que las etiquetas utilizadas para las métricas eran demócratas y republicanos. Musk, quien afirmó que no conocía las etiquetas hasta hoy, sugirió que no deberían estar allí.
Otras cosas que se consideran en relación con el tweet incluyen si tiene menos de 30 minutos, si tiene imágenes y si es un «usuario avanzado», lo que algunos dicen que significa una cuenta verificada «obsoleta « .
Hoy, la mayor parte del algoritmo de recomendación se hará de código abierto. El resto seguirá.
La prueba de fuego es que los terceros independientes deben poder determinar con una precisión razonable lo que es probable que se muestre a los usuarios.
Sin duda habrá muchos momentos incómodos… https://t.co/41U4oexIev
Musk tuiteó, junto con una publicación en el blog de la empresa, que el algoritmo de recomendación, argumentando que habría una «prueba de fuego» si «terceros independientes» pudieran «determinar con una precisión razonable lo que es probable que se muestre a los usuarios».
El lanzamiento de Twitter de su código de algoritmo se produce pocos días después de que se descubriera el código fuente más amplio de la red social en GitHub, que podría permanecer allí durante meses, según The New York Times . Luego, Twitter recibió una citación que obligaba a GitHub a revelar información sobre el cartel de GitHub.
Un informe de Platformer a principios de esta semana dijo que Twitter usó una lista secreta de los 35 principales usuarios de Twitter, incluidos el presidente Biden, LeBron James, Ben Shapiro y Musk. La evidencia de la implementación de esta lista, supuestamente impulsada en parte por la insatisfacción de Musk con su propia participación, aún no se ha encontrado en una base de código publicada en Twitter.
Específicamente, el código llega solo unas horas antes de que los usuarios «heredados verificados», aquellos que tenían una marca azul para indicar autenticidad o notoriedad antes de que Musk comprara el servicio, sean obsoletos a favor de los suscriptores pagados de Twitter Blue. Si bien algunos usuarios asociados con gobiernos y organizaciones grandes pueden solicitar otras marcas de verificación de colores , solo los suscriptores de Twitter Blue de $ 8 / mes recibirán «calificación de prioridad en las conversaciones», entre otras cosas.
Todos estos cambios tienen lugar el 1 de abril o el Día de los Inocentes.


Deja una respuesta