Generatiivne AI on lahe, kuid ärgem unustagem selle inim- ja keskkonnakulusid.

Viimaste kuude jooksul on tehisintellekti valdkond näinud kiiret kasvu ning laine laine järel on ilmunud järjest uusi mudeleid, nagu Dall-E ja GPT-4. Igal nädalal lubatakse uusi põnevaid mudeleid, tooteid ja tööriistu. Hüpelainetest on lihtne end haarata, kuid need suurepärased võimalused maksavad ühiskonnale ja planeedile.
Puudused hõlmavad haruldaste mineraalide kaevandamise keskkonnakulusid, aeganõudva andmete märkimise protsessi inimkulusid ja tehisintellekti mudelite koolitamiseks vajalikke kasvavaid rahalisi investeeringuid, kuna need sisaldavad rohkem parameetreid.
Vaatame uuendusi, mis on viinud nende mudelite uusimate põlvkondadeni ja suurendanud nendega seotud kulusid.
Suured mudelid
AI mudelid on viimastel aastatel muutunud suuremaks ja teadlased mõõdavad nüüd nende suurust sadade miljardite parameetritega. “Parameetrid” on sisemised seosed, mida mudelites kasutatakse treeningandmetel põhinevate mustrite õppimiseks.
Suurte keelemudelite (LLM) (nt ChatGPT) puhul oleme tänu Google’i PaLM-mudelile suurendanud parameetrite arvu 100 miljonilt 2018. aastal 500 miljardini 2023. aastal. Selle kasvu aluseks on teooria, et rohkemate parameetritega mudelitel peaks olema parem jõudlus isegi ülesannete puhul, mille jaoks neid algselt ei õpetatud, kuigi see hüpotees on endiselt tõestamata .
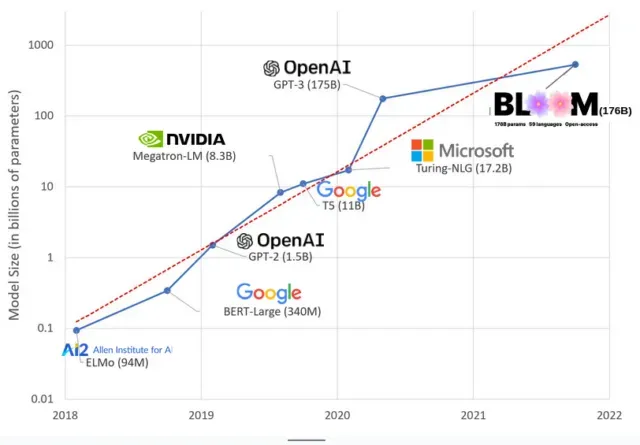
Suurte mudelite koolitamine võtab tavaliselt kauem aega, mis tähendab, et nende jaoks on vaja ka rohkem GPU-sid, mis maksavad rohkem raha, nii et ainult vähesed valitud organisatsioonid saavad neid koolitada. 175 miljardi parameetriga GPT-3 koolituse maksumus on hinnanguliselt 4,6 miljonit dollarit, mis on enamiku ettevõtete ja organisatsioonide jaoks kättesaamatu. (Väärib märkimist, et koolitusmudelite maksumus on mõnel juhul vähenenud , näiteks LLaMA puhul, mis on hiljuti Meta koolitatud mudel.)
See tekitab tehisintellekti kogukonnas digitaalse lõhe nende vahel, kes suudavad õpetada kõige eesrindlikumaid LLM-e (peamiselt suured tehnoloogiaettevõtted ja jõukad institutsioonid globaalses põhjaosas) ja nende vahel, kes ei suuda (mittetulundusühingud, idufirmad). ja igaüks, kellel pole juurdepääsu superarvutile). või miljoneid pilvekrediiti). Nende hiiglaste ehitamine ja kasutuselevõtt nõuab palju planeedi ressursse: haruldasi metalle GPU-de tootmiseks, vett tohutute andmekeskuste jahutamiseks, energiat nende andmekeskuste 24/7 töös hoidmiseks planeedi mastaabis… tähelepanu. saadud mudelite tulevikupotentsiaali kohta.
planetaarsed mõjud
Carnegie Melloni ülikooli professori Emma Strubelli uuring LLM-koolituse süsiniku jalajälje kohta näitas, et 2019. aasta mudeli nimega BERT, millel on ainult 213 miljonit parameetrit, väljaõpetamine tekitab 280 tonni süsinikdioksiidi heitkoguseid, mis on ligikaudu samaväärne viie autoga. elu. Sellest ajast alates on mudelid kasvanud ja seadmed muutunud tõhusamaks, kus me siis nüüd oleme?
Hiljutises teadustöös, mille kirjutasin, et uurida 176 miljardi parameetriga keelemudeli BLOOM-i treenimisest põhjustatud süsinikdioksiidi heitkoguseid, võrdlesime mitme LLM-i energiatarbimist ja hilisemaid süsinikdioksiidi heitkoguseid, mis kõik on viimastel aastatel välja tulnud. Võrdluse eesmärk oli saada aimu erineva suurusega LLM-emissioonide skaalast ja sellest, mis neid mõjutab.
Lisa kommentaar