Generatiivinen tekoäly on siistiä, mutta älkäämme unohtako sen ihmis- ja ympäristökustannuksia.

Muutaman viime kuukauden aikana tekoäly on kasvanut nopeasti, ja uusia malleja, kuten Dall-E ja GPT-4, on ilmestynyt aalto toisensa jälkeen. Joka viikko luvataan jännittäviä uusia malleja, tuotteita ja työkaluja. On helppo jäädä hype-aaltojen mukaan, mutta nämä loistavat mahdollisuudet maksavat yhteiskunnalle ja planeetalle.
Haittoja ovat harvinaisten mineraalien louhinnan ympäristökustannukset, aikaa vievän datamerkintäprosessin inhimilliset kustannukset ja kasvavat taloudelliset investoinnit, joita tarvitaan tekoälymallien kouluttamiseen, koska niissä on enemmän parametreja.
Katsotaanpa innovaatioita, jotka ovat johtaneet näiden mallien uusimpiin sukupolviin ja nostaneet niihin liittyviä kustannuksia.
Suuret mallit
Tekoälymallit ovat kasvaneet viime vuosina, ja tutkijat mittaavat nyt niiden kokoa sadoilla miljardeilla parametreilla. ”Parametrit” ovat sisäisiä suhteita, joita käytetään malleissa harjoitustietoihin perustuvien kuvioiden oppimiseen.
Suuret kielimallit (LLM), kuten ChatGPT, olemme lisänneet parametrien määrää 100 miljoonasta vuonna 2018 500 miljardiin vuonna 2023 Googlen PaLM-mallin ansiosta. Tämän kasvun taustalla oleva teoria on, että mallien, joissa on enemmän parametreja, pitäisi olla parempi suorituskyky jopa tehtävissä, joihin niitä ei alun perin ole koulutettu, vaikka tämä hypoteesi on edelleen todistamaton .
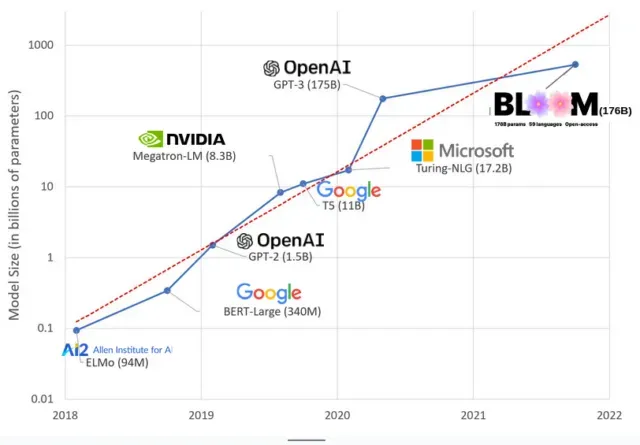
Suurien mallien kouluttaminen kestää yleensä kauemmin, mikä tarkoittaa, että ne vaativat myös enemmän GPU:ita, mikä maksaa enemmän, joten vain harvat valitut organisaatiot voivat kouluttaa niitä. GPT-3:n, jolla on 175 miljardia parametria, koulutuskustannusten arvioidaan olevan 4,6 miljoonaa dollaria, mikä on useimpien yritysten ja organisaatioiden ulottumattomissa. (On syytä huomata, että koulutusmallien kustannukset pienenevät joissakin tapauksissa , kuten LLaMA:n tapauksessa, äskettäin Metan kouluttamassa mallissa.)
Tämä luo digitaalisen kuilun tekoälyyhteisöön niiden välille, jotka voivat opettaa huippuluokan LLM-yrityksiä (enimmäkseen suuria teknologiayrityksiä ja varakkaita instituutioita globaalissa pohjoisessa) ja niiden välille, jotka eivät pysty (voittoa tavoittelemattomat yritykset, start-upit). , ja kuka tahansa, jolla ei ole pääsyä supertietokoneeseen). tai miljoonia pilvipisteitä). Näiden jättiläisten rakentaminen ja käyttöönotto vaatii paljon planeettaresursseja: harvinaisia metalleja GPU:iden valmistukseen, vettä valtavien datakeskusten jäähdyttämiseen, energiaa palvelinkeskusten pitämiseen 24/7 toiminnassa planeetan mittakaavassa… nämä kaikki jätetään usein huomiotta keskittymisen vuoksi. huomio. mallien tulevaisuuden potentiaalista.
planetaariset vaikutteet
Carnegie Mellon -yliopiston professori Emma Strubellin LLM-koulutuksen hiilijalanjäljestä tekemässä tutkimuksessa todettiin, että vuoden 2019 mallin BERT, jolla on vain 213 miljoonaa parametria, kouluttaminen tuottaa 280 tonnia hiilidioksidipäästöjä, mikä vastaa suunnilleen viittä autoa . elämää. Sittemmin mallit ovat kasvaneet ja laitteet ovat tehostuneet, joten missä olemme nyt?
Äskettäisessä tieteellisessä artikkelissa, jonka kirjoitin tutkiaksemme BLOOM-harjoittelun aiheuttamia hiilidioksidipäästöjä, 176 miljardin parametrin kielimallia, vertailimme useiden LLM-yritysten energiankulutusta ja myöhempiä hiilidioksidipäästöjä, jotka kaikki ovat tulleet julkisuuteen muutaman viime vuoden aikana. Vertailun tarkoituksena oli saada käsitys erikokoisten LLM-päästöjen laajuudesta ja niihin vaikuttavista tekijöistä.
Vastaa