L’IA generativa è interessante, ma non dimentichiamo i suoi costi umani e ambientali.

Negli ultimi mesi, il campo dell’intelligenza artificiale ha visto una rapida crescita, con ondate di nuovi modelli come Dall-E e GPT-4 che si sono susseguiti. Ogni settimana vengono promessi nuovi entusiasmanti modelli, prodotti e strumenti. È facile lasciarsi trasportare dalle ondate di pubblicità, ma queste brillanti opportunità hanno un costo per la società e il pianeta.
Gli svantaggi includono il costo ambientale dell’estrazione di minerali rari, il costo umano del lungo processo di annotazione dei dati e il crescente investimento finanziario necessario per addestrare i modelli di intelligenza artificiale poiché includono più parametri.
Diamo uno sguardo alle innovazioni che hanno portato alle ultime generazioni di questi modelli e hanno fatto lievitare i costi ad essi associati.
Grandi modelli
I modelli di intelligenza artificiale sono diventati più grandi negli ultimi anni, con i ricercatori che ora misurano le loro dimensioni in centinaia di miliardi di parametri. I “parametri” sono relazioni interne utilizzate nei modelli per apprendere modelli basati su dati di addestramento.
Per i modelli di linguaggio di grandi dimensioni (LLM) come ChatGPT, abbiamo aumentato il numero di parametri da 100 milioni nel 2018 a 500 miliardi nel 2023 grazie al modello PaLM di Google. La teoria alla base di questa crescita è che i modelli con più parametri dovrebbero avere prestazioni migliori anche su attività su cui non erano stati originariamente addestrati, sebbene questa ipotesi rimanga non dimostrata .
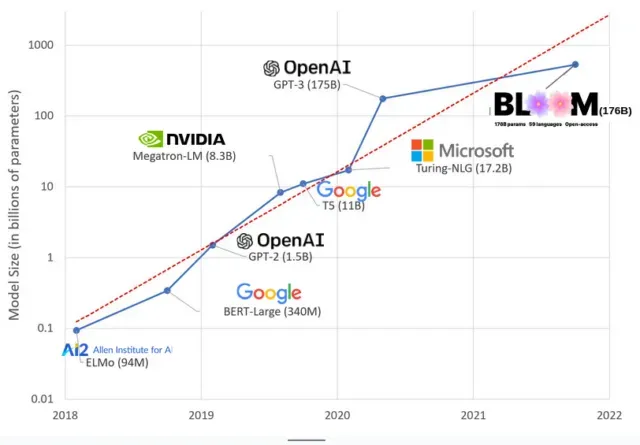
I modelli di grandi dimensioni di solito richiedono più tempo per l’addestramento, il che significa che richiedono anche più GPU, che costano di più, quindi solo poche organizzazioni selezionate possono addestrarli. Il costo dell’addestramento di GPT-3, che ha 175 miliardi di parametri, è stimato a 4,6 milioni di dollari, che è fuori portata per la maggior parte delle aziende e delle organizzazioni. (Vale la pena notare che il costo dei modelli di addestramento è ridotto in alcuni casi , come nel caso di LLaMA, un recente modello addestrato da Meta.)
Questo sta creando un divario digitale nella comunità AI tra coloro che possono insegnare agli LLM più all’avanguardia (principalmente grandi aziende tecnologiche e istituzioni ricche nel Nord del mondo) e coloro che non possono (non profit, start-up e chiunque non abbia accesso a un supercomputer). o milioni in crediti cloud). Costruire e implementare questi giganti richiede molte risorse planetarie: metalli rari per produrre GPU, acqua per raffreddare enormi data center, energia per mantenere quei data center in funzione 24 ore su 24, 7 giorni su 7 su scala planetaria… Attenzione. sul potenziale futuro dei modelli risultanti.
influenze planetarie
Uno studio della professoressa della Carnegie Mellon University Emma Strubell sull’impronta di carbonio della formazione LLM ha rilevato che l’addestramento di un modello del 2019 chiamato BERT, che ha solo 213 milioni di parametri, emette 280 tonnellate di emissioni di carbonio, all’incirca l’equivalente di cinque automobili. vita. Da allora, i modelli sono cresciuti e le attrezzature sono diventate più efficienti, quindi a che punto siamo?
In un recente articolo scientifico che ho scritto per studiare le emissioni di carbonio causate dall’allenamento BLOOM, un modello linguistico con 176 miliardi di parametri, abbiamo confrontato il consumo di energia e le conseguenti emissioni di carbonio di diversi LLM, tutti usciti negli ultimi anni. Lo scopo del confronto era quello di avere un’idea della portata delle emissioni LLM di diverse dimensioni e di cosa le influenza.
Lascia un commento