Twitter pubblica il codice che sostiene determina quali tweet le persone vedono e perché.
Twitter ha mantenuto una delle tante promesse del CEO Elon Musk pubblicando venerdì pomeriggio quello che sostiene sia il codice per il suo algoritmo di raccomandazione dei tweet su GitHub .
Il codice, pubblicato sotto la GNU Affero v3.0 General Public License , contiene numerosi dettagli su quali fattori rendono più o meno probabile che un tweet appaia nella timeline di un utente.
In un post sul blog che accompagna il rilascio del codice , il team di ingegneri di Twitter (senza una didascalia specifica) osserva che il sistema per determinare quali sono “i tweet più popolari che finiscono per essere visualizzati sulla timeline del tuo dispositivo” “comprende molti servizi e lavori interconnessi”.
La più grande fonte di questi tweet sono “fonti online” o utenti che vengono seguiti da qualcuno. I migliori tweet di questo stack sono classificati in base alla probabilità che un utente interagisca con l’autore di quel tweet; più è probabile che i loro tweet appaiano in For You. Per le “fonti offline” non seguite dall’utente, Twitter afferma di considerare i tweet che attirano l’attenzione delle persone che l’utente segue e i tweet che piacciono a coloro a cui piacciono i tweet simili all’utente.
Già chi ha guardato il codice ha notato considerazioni che sollevano molte più domande. Molti li hanno pubblicati, ovviamente, su Twitter stesso.
Twitter ha appena rilasciato il codice sorgente dell ‘”algoritmo”.
Oh cos’è questo file? Predicati per i tweet sulla timeline domestica?
Oh cos’è quella seconda foto? pic.twitter.com/UE3dU8e3Os
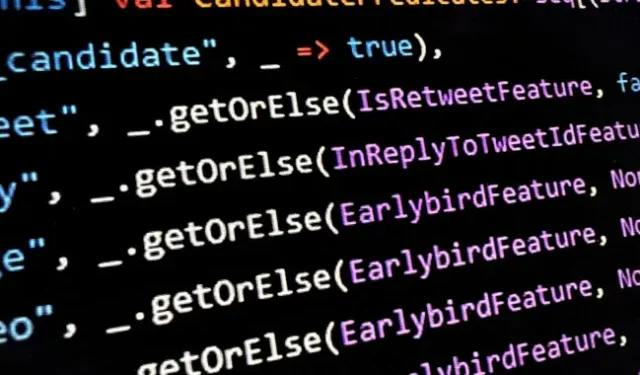
Olafur Vaage, ingegnere informatico senior presso il servizio di consulenza software norvegese TurtleSec, ha osservato che all’interno di ” HomeTweetTypePredicates.scala “alcune delle possibili considerazioni per le quali un tweet potrebbe essere un candidato per la sezione “For You” sono le seguenti:
-
author_is_elon -
author_is_power_user -
author_is_democrat -
author_is_republican
Altrove nel codice, un commento in codice presumibilmente lasciato da un ingegnere di Twitter chiarisce che questi valori di identificazione sono “utilizzati esclusivamente per raccogliere metriche”. Il commento è questo:
Questi elenchi di ID autore vengono utilizzati esclusivamente per la raccolta di metriche. Teniamo traccia della frequenza con cui pubblichiamo i tweet di questi autori e della frequenza con cui i loro tweet impressionano gli utenti. Questo ci aiuta a confermare sulla nostra piattaforma di sperimentazione A/B che non stiamo inviando modifiche che hanno un impatto negativo su un gruppo rispetto ad altri.
I nomi degli oggetti in questione, come “DDGStatsDemocratsFeature” o “DDGStatsElonFeature” sembrano supportare questa interpretazione, ma potrebbe non essere possibile confermarla con il codice disponibile. Tuttavia, è interessante che Twitter verifichi e correli queste variabili. Durante la sessione audio di Twitter Spaces, un ingegnere di Twitter ha notato che le etichette utilizzate per le metriche erano Democratici e Repubblicani. Musk, che ha affermato di non essere a conoscenza delle etichette fino ad oggi, ha suggerito che non dovrebbero esserci.
Altre cose che vengono considerate in relazione al tweet includono se ha meno di 30 minuti, se ha immagini e se si tratta di un “utente esperto”, che secondo alcuni significa un account verificato “obsoleto “ .
Oggi, la maggior parte dell’algoritmo di raccomandazione sarà reso open source. Il resto seguirà.
La prova del fuoco è che terze parti indipendenti devono essere in grado di determinare con ragionevole accuratezza ciò che è probabile che venga mostrato agli utenti.
Senza dubbio ci saranno molti momenti imbarazzanti… https://t.co/41U4oexIev
Musk ha twittato, insieme a un post sul blog aziendale, che l’algoritmo di raccomandazione, sostenendo che ci sarebbe un “test del fuoco” se “terze parti indipendenti” potessero “determinare con ragionevole precisione ciò che è probabile che venga mostrato agli utenti”.
Il rilascio del codice dell’algoritmo da parte di Twitter arriva pochi giorni dopo che il codice sorgente più ampio del social network è stato scoperto su GitHub, potenzialmente rimasto lì per mesi, secondo il New York Times . Twitter ha quindi ricevuto un mandato di comparizione che costringe GitHub a rivelare informazioni sul poster di GitHub.
Un rapporto di Platformer all’inizio di questa settimana ha affermato che Twitter ha utilizzato un elenco segreto di 35 principali utenti di Twitter, tra cui il presidente Biden, LeBron James, Ben Shapiro e Musk. La prova dell’implementazione di questo elenco, secondo quanto riferito in parte dall’insoddisfazione di Musk per il proprio coinvolgimento, deve ancora essere trovata in una base di codice pubblicata su Twitter.
Nello specifico, il codice arriva solo poche ore prima che gli utenti “eredità verificati” – quelli che avevano il segno di spunta blu per indicare l’autenticità o la notorietà prima che Musk acquistasse il servizio – dovrebbero essere deprecati a favore degli abbonati a pagamento di Twitter Blue. Mentre alcuni utenti associati a governi e grandi organizzazioni possono richiedere altri segni di spunta colorati , solo $ 8 al mese Gli abbonati a Twitter Blue riceveranno tra le altre cose “valutazione di priorità nelle conversazioni”.
Tutti questi cambiamenti hanno luogo il 1° aprile o il primo di aprile.


Lascia un commento