Generatyvus dirbtinis intelektas yra šaunus, tačiau nepamirškime jo žmogiškųjų ir aplinkosaugos išlaidų.

Per pastaruosius kelis mėnesius dirbtinio intelekto sritis sparčiai augo ir vienas po kito atsirado naujų modelių, tokių kaip Dall-E ir GPT-4. Kiekvieną savaitę žadama naujų įdomių modelių, gaminių ir įrankių. Lengva pasitraukti iš ažiotažo bangų, tačiau šios puikios galimybės kainuoja visuomenei ir planetai.
Trūkumai apima retų mineralų gavybos išlaidas aplinkai, daug laiko reikalaujančio duomenų anotavimo proceso išlaidas ir didėjančias finansines investicijas, reikalingas dirbtinio intelekto modeliams parengti, nes juose yra daugiau parametrų.
Pažvelkime į naujoves, kurios atvedė prie naujausių šių modelių kartų ir padidino su jais susijusias išlaidas.
Dideli modeliai
AI modeliai pastaraisiais metais tapo didesni, o dabar mokslininkai matuoja jų dydį šimtais milijardų parametrų. „Parametrai“ yra vidiniai ryšiai, naudojami modeliuose, siekiant išmokti modelius, pagrįstus mokymo duomenimis.
Didelių kalbų modelių (LLM), pvz., „ChatGPT“, parametrų skaičių padidinome nuo 100 mln. 2018 m. iki 500 mlrd. 2023 m. dėl „Google“ PaLM modelio. Šio augimo teorija yra ta, kad modeliai su daugiau parametrų turėtų geriau veikti net atliekant užduotis, kurių jie iš pradžių nebuvo mokomi, nors ši hipotezė lieka neįrodyta .
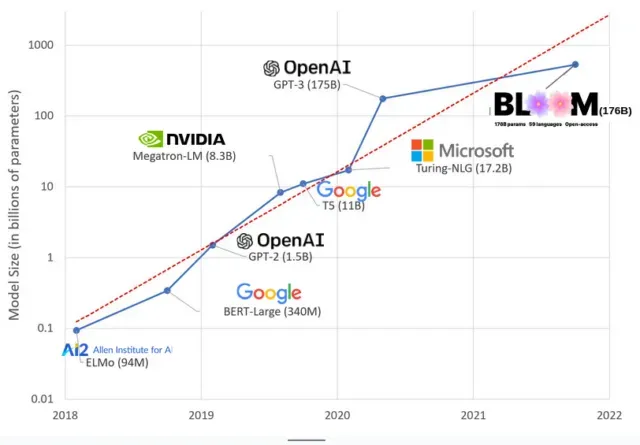
Dideli modeliai paprastai apmokomi ilgiau, o tai reiškia, kad jiems taip pat reikia daugiau GPU, o tai kainuoja daugiau pinigų, todėl tik kelios organizacijos gali juos apmokyti. Apskaičiuota, kad GPT-3, turinčio 175 milijardus parametrų, mokymo kaina yra 4,6 mln. USD, o tai nepasiekiama daugumai įmonių ir organizacijų. (Verta pažymėti, kad kai kuriais atvejais mokymo modelių kaina yra sumažinta , pavyzdžiui, LLaMA, neseniai parengto Meta modelio, atveju.)
Tai sukuria skaitmeninę atskirtį dirbtinio intelekto bendruomenėje tarp tų, kurie gali mokyti pažangiausius LLM (dažniausiai didelės technologijų įmonės ir turtingos pasaulio šiaurės institucijos) ir tų, kurie to negali (pelno nesiekiančios organizacijos, besikuriančios įmonės). , ir visi, kurie neturi prieigos prie superkompiuterio). arba milijonai debesų kreditų). Norint sukurti ir įdiegti šiuos milžinus, reikia daug planetos išteklių: retų metalų, skirtų GPU gaminti, vandens didžiuliams duomenų centrams aušinti, energijos, kad tie duomenų centrai veiktų visą parą planetos mastu… dėmesį. apie gautų modelių ateities potencialą.
planetinės įtakos
Carnegie Mellon universiteto profesorės Emmos Strubell tyrimas apie LLM mokymų anglies pėdsaką atskleidė, kad 2019 m. modelio, pavadinto BERT, kuris turi tik 213 milijonų parametrų, mokymas išmeta 280 metrinių tonų anglies dvideginio, ty maždaug penkių automobilių ekvivalentas. gyvenimą. Nuo tada modeliai augo, o įranga tapo efektyvesnė, tad kur mes dabar?
Neseniai paskelbtame moksliniame darbe, kurį rašiau norėdamas ištirti anglies dvideginio išmetimą, kurį sukelia mokymas BLOOM, kalbos modelis su 176 milijardais parametrų, palyginome kelių LLM energijos suvartojimą ir vėlesnį anglies dvideginio išmetimą, kurie visi pasirodė per pastaruosius kelerius metus. Palyginimo tikslas buvo susidaryti supratimą apie įvairių dydžių LLM emisijų mastą ir kas joms įtakoja.
Parašykite komentarą