Ģeneratīvais mākslīgais intelekts ir foršs, taču neaizmirsīsim par tā izmaksām cilvēkiem un videi.

Pēdējo dažu mēnešu laikā mākslīgā intelekta joma ir piedzīvojusi strauju izaugsmi, un viens pēc otra ir parādījušies jauni modeļi, piemēram, Dall-E un GPT-4. Katru nedēļu tiek solīti aizraujoši jauni modeļi, produkti un instrumenti. Ir viegli aizraut ažiotāžu viļņos, taču šīs izcilās iespējas sabiedrībai un planētai maksā.
Trūkumi ietver reto minerālu ieguves vides izmaksas, laikietilpīgā datu anotācijas procesa izmaksas un pieaugošos finanšu ieguldījumus, kas nepieciešami AI modeļu apmācībai, jo tie ietver vairāk parametru.
Apskatīsim jauninājumus, kas ir noveduši pie šo modeļu jaunākās paaudzes un ir palielinājuši ar tiem saistītās izmaksas.
Lielie modeļi
AI modeļi pēdējos gados ir kļuvuši lielāki, un pētnieki tagad mēra to izmēru simtiem miljardu parametru. “Parametri” ir iekšējās attiecības, ko izmanto modeļos, lai apgūtu modeļus, pamatojoties uz apmācības datiem.
Pateicoties Google PaLM modelim, lielajiem valodu modeļiem (LLM), piemēram, ChatGPT, esam palielinājuši parametru skaitu no 100 miljoniem 2018. gadā līdz 500 miljardiem 2023. gadā. Šīs izaugsmes pamatā ir teorija , ka modeļiem ar vairāk parametru vajadzētu būt labākiem pat uzdevumos, par kuriem tie sākotnēji netika apmācīti, lai gan šī hipotēze joprojām nav pierādīta .
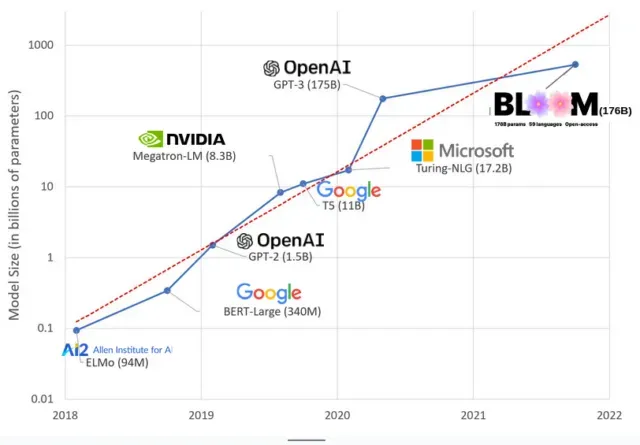
Lielu modeļu apmācība parasti aizņem ilgāku laiku, kas nozīmē, ka tiem ir nepieciešams arī vairāk GPU, kas maksā vairāk naudas, tāpēc tikai dažas atlasītās organizācijas var tos apmācīt. GPT-3 apmācības izmaksas , kurām ir 175 miljardi parametru, tiek lēstas 4,6 miljonu ASV dolāru apmērā, kas lielākajai daļai uzņēmumu un organizāciju nav sasniedzamas. (Ir vērts atzīmēt, ka dažos gadījumos apmācības modeļu izmaksas tiek samazinātas , piemēram, LLaMA gadījumā, kas ir nesen Meta apmācīts modelis.)
Tas rada digitālu plaisu AI kopienā starp tiem, kuri var mācīt visprogresīvākos LLM (galvenokārt lielie tehnoloģiju uzņēmumi un bagātas institūcijas globālajos ziemeļos) un tiem, kuri nevar (bezpeļņas uzņēmumi, jaunuzņēmumi). un ikvienam, kam nav piekļuves superdatoram). vai miljoniem mākoņa kredītos). Lai izveidotu un ieviestu šos milžus, ir nepieciešami daudzi planētu resursi: reti metāli, lai ražotu GPU, ūdens, lai atdzesētu milzīgus datu centrus, enerģija, lai šie datu centri darbotos 24/7 planētas mērogā… tas viss bieži tiek ignorēts par labu fokusēšanai. uzmanību. par iegūto modeļu nākotnes potenciālu.
planētu ietekmes
Kārnegija Melona universitātes profesores Emmas Strubellas pētījums par LLM apmācības oglekļa pēdu atklāja, ka, apmācot 2019. gada modeli ar nosaukumu BERT, kuram ir tikai 213 miljoni parametru, tiek izmesti 280 metriskās tonnas oglekļa emisiju, kas ir aptuveni ekvivalents piecu automašīnu emisijām. dzīvi. Kopš tā laika modeļi ir auguši un aprīkojums ir kļuvis efektīvāks, tad kur mēs esam tagad?
Nesenā zinātniskajā rakstā, ko rakstīju, lai izpētītu oglekļa emisijas, ko izraisa apmācība BLOOM — valodas modelis ar 176 miljardiem parametru, mēs salīdzinājām vairāku LLM enerģijas patēriņu un turpmākās oglekļa emisijas, kas visas ir iznākušas pēdējos gados. Salīdzinājuma mērķis bija iegūt priekšstatu par dažāda lieluma LLM emisiju mērogu un to, kas to ietekmē.
Atbildēt