Twitter publiceert code die naar eigen zeggen bepaalt welke tweets mensen zien en waarom.
Twitter maakte een van de vele beloften van CEO Elon Musk waar door op vrijdagmiddag te posten wat volgens hem de code is voor zijn tweet-aanbevelingsalgoritme op GitHub .
De code, gepubliceerd onder de GNU Affero v3.0 General Public License , bevat tal van details over welke factoren ervoor zorgen dat een tweet meer of minder waarschijnlijk verschijnt in de tijdlijn van een gebruiker.
In een blogpost bij de release van de code merkt het technische team van Twitter (zonder een specifiek bijschrift) op dat het systeem om te bepalen welke “de meest populaire tweets zijn die voor jou op de tijdlijn van je apparaat verschijnen” veel onderling verbonden diensten en banen omvat.
De grootste bron van deze tweets zijn “online bronnen” oftewel gebruikers die door iemand gevolgd worden. De beste tweets van deze stapel worden gerangschikt op basis van de waarschijnlijkheid dat een gebruiker interactie heeft met de auteur van die tweet; hoe groter de kans dat hun tweets in For You verschijnen. Voor “offline bronnen” die niet door de gebruiker worden gevolgd, zegt Twitter dat het tweets overweegt die de aandacht trekken van mensen die de gebruiker volgt en tweets die leuk zijn voor degenen die van tweets houden die vergelijkbaar zijn met de gebruiker.
Wie de code heeft bekeken, heeft al overwegingen opgemerkt die veel meer vragen oproepen. Velen plaatsten ze natuurlijk op Twitter zelf.
Twitter heeft zojuist de broncode van het “algoritme” vrijgegeven.
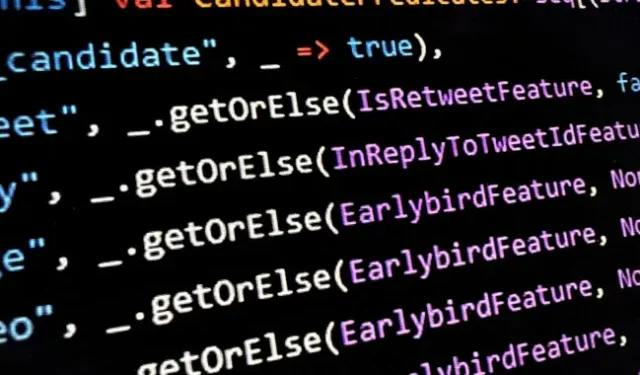
Oh wat is dit bestand? Predikaten voor tweets op de tijdlijn thuis?
Oh wat is die tweede foto? pic.twitter.com/UE3dU8e3Os
Olafur Vaage, senior software-engineer bij de Noorse software-adviesdienst TurtleSec, merkte op dat binnen ” HomeTweetTypePredicates.scala “enkele van de mogelijke overwegingen waarvoor een tweet een kandidaat zou kunnen zijn voor de sectie “Voor jou” de volgende zijn:
-
author_is_elon -
author_is_power_user -
author_is_democrat -
author_is_republican
Elders in de code verduidelijkt een codecommentaar, zogenaamd achtergelaten door een Twitter-engineer, dat deze identificatiewaarden “uitsluitend worden gebruikt voor het verzamelen van statistieken”. De opmerking gaat als volgt:
Deze auteurs-ID-lijsten worden uitsluitend gebruikt voor het verzamelen van statistieken. We houden bij hoe vaak we de tweets van deze auteurs weergeven en hoe vaak hun tweets indruk maken op gebruikers. Dit helpt ons om op ons platform voor A/B-experimenten te bevestigen dat we geen wijzigingen indienen die een negatieve invloed hebben op de ene groep ten opzichte van de andere.
De namen van de objecten in kwestie, zoals “DDGStatsDemocratsFeature” of “DDGStatsElonFeature”, lijken deze interpretatie te ondersteunen, maar dit kan mogelijk niet worden bevestigd met de beschikbare code. Het is echter interessant dat Twitter deze variabelen controleert en correleert. Tijdens de audiosessie van Twitter Spaces merkte een Twitter-technicus op dat de labels die voor de statistieken werden gebruikt, Democraten en Republikeinen waren. Musk, die beweerde dat hij tot vandaag niets van de labels wist, stelde voor dat ze er niet zouden moeten zijn.
Andere dingen die worden overwogen met betrekking tot de tweet, zijn onder meer of deze minder dan 30 minuten oud is, of deze afbeeldingen bevat en of het een “hoofdgebruiker” is, wat volgens sommigen een “verouderd” geverifieerd account betekent .
Vandaag zal het grootste deel van het aanbevelingsalgoritme open source worden gemaakt. De rest zal volgen.
De zuurtest is dat onafhankelijke derde partijen met redelijke nauwkeurigheid moeten kunnen bepalen wat waarschijnlijk aan gebruikers wordt getoond.
Er zullen ongetwijfeld veel ongemakkelijke momenten zijn … https://t.co/41U4oexIev
Musk tweette, samen met een blogpost van het bedrijf, dat het aanbevelingsalgoritme, met het argument dat er een “zuurtest” zou zijn als “onafhankelijke derden” “met redelijke nauwkeurigheid zouden kunnen bepalen wat waarschijnlijk aan gebruikers wordt getoond”.
Twitter’s release van zijn algoritmecode komt slechts enkele dagen nadat de bredere broncode van het sociale netwerk werd ontdekt op GitHub, die daar mogelijk maanden heeft gestaan, volgens The New York Times . Twitter ontving vervolgens een dagvaarding die GitHub dwong om informatie over de GitHub-poster vrij te geven.
Een rapport van Platformer eerder deze week zei dat Twitter een geheime lijst gebruikte van 35 top Twitter-gebruikers, waaronder president Biden, LeBron James, Ben Shapiro en Musk. Bewijs van de implementatie van deze lijst, naar verluidt gedeeltelijk ingegeven door Musks ontevredenheid over zijn eigen betrokkenheid, moet nog worden gevonden in een codebase die op Twitter is geplaatst.
Concreet arriveert de code slechts een paar uur voordat “geverifieerde legacy” -gebruikers – degenen die blauw waren aangevinkt om authenticiteit of bekendheid aan te geven voordat Musk de dienst kocht – worden afgeschaft ten gunste van betaalde Twitter Blue-abonnees. Hoewel sommige gebruikers die banden hebben met overheden en grote organisaties andere gekleurde vinkjes kunnen aanvragen , ontvangen Twitter Blue-abonnees voor slechts $ 8/maand onder andere “prioriteitsclassificatie in gesprekken” .
Al deze veranderingen vinden plaats op 1 april of 1 april.


Geef een reactie