Generatywna sztuczna inteligencja jest fajna, ale nie zapominajmy o kosztach ludzkich i środowiskowych.

W ciągu ostatnich kilku miesięcy dziedzina sztucznej inteligencji odnotowała szybki wzrost, a kolejne modele, takie jak Dall-E i GPT-4, pojawiały się jedna po drugiej. Co tydzień obiecujemy ekscytujące nowe modele, produkty i narzędzia. Łatwo dać się ponieść fali szumu, ale te wspaniałe możliwości mają swoją cenę dla społeczeństwa i planety.
Wady obejmują środowiskowy koszt wydobycia rzadkich minerałów, koszt ludzki związany z czasochłonnym procesem adnotacji danych oraz rosnące inwestycje finansowe wymagane do szkolenia modeli AI, ponieważ obejmują one więcej parametrów.
Przyjrzyjmy się innowacjom, które doprowadziły do powstania najnowszych generacji tych modeli i spowodowały wzrost kosztów z nimi związanych.
Duże modele
Modele sztucznej inteligencji powiększyły się w ostatnich latach, a naukowcy mierzą teraz ich rozmiar w setkach miliardów parametrów. „Parametry” to wewnętrzne relacje używane w modelach do uczenia się wzorców na podstawie danych treningowych.
W przypadku dużych modeli językowych (LLM), takich jak ChatGPT, zwiększyliśmy liczbę parametrów ze 100 milionów w 2018 r. do 500 miliardów w 2023 r. dzięki modelowi Google PaLM. Teoria stojąca za tym wzrostem jest taka, że modele z większą liczbą parametrów powinny mieć lepszą wydajność nawet w zadaniach, w których nie były pierwotnie szkolone, chociaż ta hipoteza pozostaje niesprawdzona .
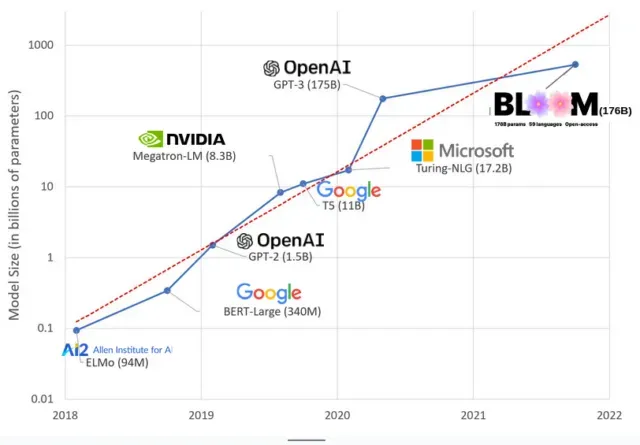
Trenowanie dużych modeli zajmuje zwykle więcej czasu, co oznacza, że wymagają one również większej liczby procesorów graficznych, które kosztują więcej pieniędzy, więc tylko kilka wybranych organizacji może je szkolić. Koszt szkolenia GPT-3, który ma 175 miliardów parametrów, szacuje się na 4,6 miliona dolarów, co jest poza zasięgiem większości firm i organizacji. (Warto zauważyć, że koszt szkolenia modeli jest w niektórych przypadkach obniżony , na przykład w przypadku LLaMA, najnowszego modelu trenowanego przez Meta.)
Tworzy to cyfrową przepaść w społeczności sztucznej inteligencji między tymi, którzy mogą uczyć najnowocześniejsze LLM (głównie duże firmy technologiczne i bogate instytucje na Globalnej Północy), a tymi, którzy nie mogą (organizacje non-profit, start-upy) i każdego, kto nie ma dostępu do superkomputera). lub miliony kredytów w chmurze). Budowa i wdrażanie tych gigantów wymaga wielu zasobów planetarnych: rzadkich metali do produkcji procesorów graficznych, wody do chłodzenia ogromnych centrów danych, energii do utrzymania tych centrów danych w trybie 24/7 na skalę planetarną… wszystko to jest często pomijane na rzecz skupienia się uwaga. o przyszłym potencjale powstałych modeli.
wpływy planetarne
Badanie przeprowadzone przez profesor Carnegie Mellon University, Emmę Strubell, dotyczące śladu węglowego szkolenia LLM wykazało, że szkolenie modelu 2019 o nazwie BERT, który ma tylko 213 milionów parametrów, emituje 280 ton metrycznych emisji dwutlenku węgla, co w przybliżeniu odpowiada pięciu samochodom. życie. Od tego czasu modele urosły, a sprzęt stał się bardziej wydajny, więc gdzie jesteśmy teraz?
W niedawnym artykule naukowym, który napisałem, aby zbadać emisję dwutlenku węgla spowodowaną szkoleniem BLOOM, model języka ze 176 miliardami parametrów, porównaliśmy zużycie energii i późniejszą emisję dwutlenku węgla przez kilka LLM, z których wszystkie pojawiły się w ciągu ostatnich kilku lat. Celem porównania było zorientowanie się, jaka jest skala emisji LLM o różnych rozmiarach i co na nie wpływa.
Dodaj komentarz