A IA generativa é legal, mas não vamos esquecer seus custos humanos e ambientais.

Nos últimos meses, o campo da inteligência artificial teve um rápido crescimento, com onda após onda de novos modelos, como Dall-E e GPT-4, aparecendo um após o outro. Novos modelos, produtos e ferramentas emocionantes são prometidos todas as semanas. É fácil se deixar levar pelas ondas do hype, mas essas oportunidades brilhantes têm um custo para a sociedade e para o planeta.
As desvantagens incluem o custo ambiental da mineração de minerais raros, o custo humano do demorado processo de anotação de dados e o crescente investimento financeiro necessário para treinar modelos de IA, pois incluem mais parâmetros.
Vamos dar uma olhada nas inovações que levaram às últimas gerações desses modelos e aumentaram os custos associados a eles.
modelos grandes
Os modelos de IA ficaram maiores nos últimos anos, com os pesquisadores medindo seu tamanho em centenas de bilhões de parâmetros. “Parâmetros” são relacionamentos internos usados em modelos para aprender padrões com base em dados de treinamento.
Para modelos de linguagem grandes (LLMs) como ChatGPT, aumentamos o número de parâmetros de 100 milhões em 2018 para 500 bilhões em 2023 graças ao modelo PaLM do Google. A teoria por trás desse crescimento é que modelos com mais parâmetros devem ter melhor desempenho mesmo em tarefas nas quais não foram originalmente treinados, embora essa hipótese permaneça sem comprovação .
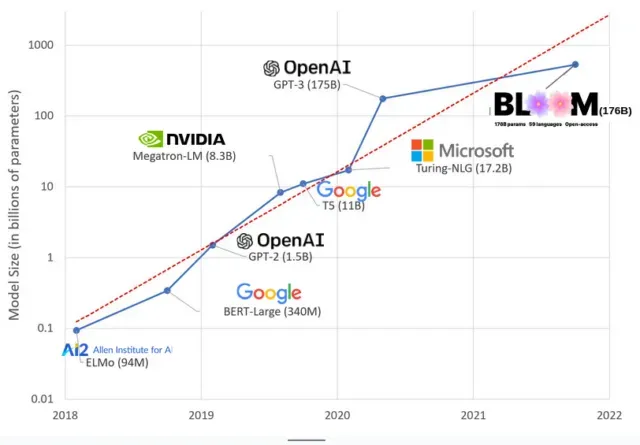
Modelos grandes geralmente levam mais tempo para treinar, o que significa que também exigem mais GPUs, que custam mais dinheiro, portanto, apenas algumas organizações selecionadas podem treiná-los. O custo do treinamento do GPT-3, que possui 175 bilhões de parâmetros, é estimado em US$ 4,6 milhões, o que está fora do alcance da maioria das empresas e organizações. (Vale ressaltar que o custo dos modelos de treinamento é reduzido em alguns casos , como no caso do LLaMA, modelo recente treinado pela Meta.)
Isso está criando uma divisão digital na comunidade de IA entre aqueles que podem ensinar os LLMs mais avançados (principalmente grandes empresas de tecnologia e instituições ricas no Norte Global) e aqueles que não podem (organizações sem fins lucrativos, start-ups , e qualquer pessoa que não tenha acesso a um supercomputador). ou milhões em créditos de nuvem). Construir e implantar esses gigantes requer muitos recursos planetários: metais raros para fabricar GPUs, água para resfriar enormes data centers, energia para manter esses data centers funcionando 24 horas por dia, 7 dias por semana em escala planetária… atenção. sobre o potencial futuro dos modelos resultantes.
influências planetárias
Um estudo da professora Emma Strubell da Carnegie Mellon University sobre a pegada de carbono do treinamento LLM descobriu que treinar um modelo 2019 chamado BERT, que tem apenas 213 milhões de parâmetros, emite 280 toneladas métricas de emissões de carbono, aproximadamente o equivalente a cinco carros. vida. Desde então, os modelos cresceram e os equipamentos se tornaram mais eficientes, então onde estamos agora?
Em um artigo científico recente que escrevi para estudar as emissões de carbono causadas pelo treinamento do BLOOM, um modelo de linguagem com 176 bilhões de parâmetros, comparamos o consumo de energia e as subsequentes emissões de carbono de vários LLMs, todos lançados nos últimos anos. O objetivo da comparação era ter uma ideia da escala das emissões LLM de diferentes tamanhos e o que as influencia.
Deixe um comentário