O Twitter publica um código que afirma determinar quais tweets as pessoas veem e por quê.
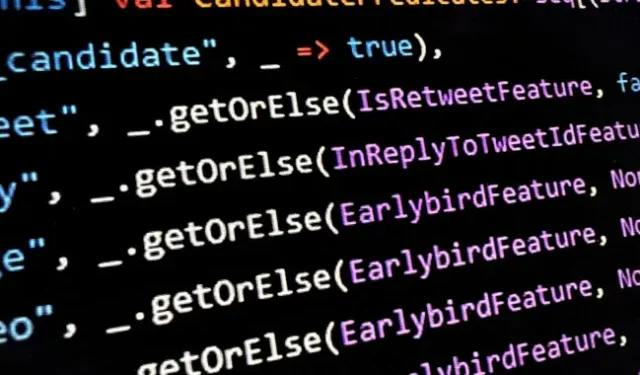
O Twitter cumpriu uma das muitas promessas do CEO Elon Musk ao postar na tarde de sexta-feira o que afirma ser o código para seu algoritmo de recomendação de tweets no GitHub .
O código, publicado sob a Licença Pública Geral GNU Affero v3.0 , contém vários detalhes sobre quais fatores tornam um tweet mais ou menos provável de aparecer na linha do tempo de um usuário.
Em uma postagem de blog que acompanha o lançamento do código , a equipe de engenharia do Twitter (sem uma legenda específica) observa que o sistema para determinar quais são “os tweets mais populares que acabam aparecendo na linha do tempo do seu dispositivo para você” “compreende muitos serviços e trabalhos interconectados”.
A maior fonte desses tweets são “fontes online” ou usuários que estão sendo seguidos por alguém. Os tweets principais dessa pilha são classificados pela probabilidade de um usuário interagir com o autor desse tweet; maior a probabilidade de seus tweets aparecerem em For You. Para “fontes off-line” não seguidas pelo usuário, o Twitter diz que considera tuítes que chamam a atenção de pessoas que o usuário segue e tuítes que são curtidos por quem gosta de tuítes parecidos com o usuário.
Já aqueles que examinaram o código notaram considerações que levantam muitas outras questões. Muitos os postaram, é claro, no próprio Twitter.
O Twitter acaba de liberar o código-fonte do “algoritmo”.
Oi, o que é esse arquivo? Predicados para tweets na linha do tempo doméstica?
Oi, qual é a segunda foto? pic.twitter.com/UE3dU8e3Os
Olafur Vaage, engenheiro de software sênior do serviço de consultoria de software norueguês TurtleSec, observou que dentro de “ HomeTweetTypePredicates.scala “algumas das possíveis considerações para as quais um tweet poderia ser candidato à seção “Para você” são as seguintes:
-
author_is_elon -
author_is_power_user -
author_is_democrat -
author_is_republican
Em outra parte do código, um comentário de código supostamente deixado por um engenheiro do Twitter esclarece que esses valores de identificação são “usados exclusivamente para coletar métricas”. O comentário fica assim:
Essas listas de ID de autor são usadas exclusivamente para coletar métricas. Rastreamos com que frequência veiculamos os tweets desses autores e com que frequência seus tweets impressionam os usuários. Isso nos ajuda a confirmar em nossa plataforma de experimentação A/B que não estamos enviando alterações que impactam negativamente um grupo em detrimento de outros.
Os nomes dos objetos em questão, como “DDGStatsDemocratsFeature” ou “DDGStatsElonFeature” parecem apoiar essa interpretação, mas isso pode não ser possível confirmar com o código disponível. No entanto, é interessante que o Twitter verifique e correlacione essas variáveis. Durante a sessão de áudio do Twitter Spaces, um engenheiro do Twitter observou que os rótulos usados para as métricas eram democratas e republicanos. Musk, que alegou não saber sobre os rótulos até hoje, sugeriu que eles não deveriam estar lá.
Outras coisas que são consideradas em relação ao tweet incluem se ele tem menos de 30 minutos, se tem imagens e se é um “usuário avançado”, que alguns dizem significar uma conta verificada “desatualizada ” .
Hoje, a maior parte do algoritmo de recomendação será de código aberto. O resto seguirá.
O teste decisivo é que terceiros independentes devem ser capazes de determinar com precisão razoável o que provavelmente será mostrado aos usuários.
Sem dúvida haverá muitos momentos constrangedores… https://t.co/41U4oexIev
Musk twittou, junto com uma postagem no blog da empresa, que o algoritmo de recomendação, argumentando que haveria um “teste de ácido” se “terceiros independentes” pudessem “determinar com precisão razoável o que provavelmente seria mostrado aos usuários”.
O lançamento de seu código de algoritmo pelo Twitter ocorre apenas alguns dias depois que o código-fonte mais amplo da rede social foi descoberto no GitHub, potencialmente parado por meses, de acordo com o The New York Times . O Twitter então recebeu uma intimação forçando o GitHub a revelar informações sobre o pôster do GitHub.
Um relatório da Platformer no início desta semana disse que o Twitter usou uma lista secreta dos 35 principais usuários do Twitter, incluindo o presidente Biden, LeBron James, Ben Shapiro e Musk. A evidência da implementação desta lista, supostamente motivada em parte pela insatisfação de Musk com seu próprio envolvimento, ainda não foi encontrada em uma base de código postada no Twitter.
Especificamente, o código chega apenas algumas horas antes dos usuários “herdados verificados” – aqueles que foram marcados em azul para indicar autenticidade ou notoriedade antes de Musk comprar o serviço – serem substituídos por assinantes pagos do Twitter Blue. Embora alguns usuários associados a governos e grandes organizações possam solicitar outras marcas de seleção coloridas , assinantes do Twitter Blue de apenas US$ 8/mês receberão “classificação prioritária em conversas”, entre outras coisas.
Todas essas mudanças ocorrem em 1º de abril, ou Dia da Mentira.


Deixe um comentário