生成式人工智能很酷,但我們不要忘記它的人力和環境成本。

過去幾個月,人工智能領域快速發展,Dall-E、GPT-4等一波又一波的新模型相繼出現。每週都會推出令人興奮的新模型、產品和工具。人們很容易被一波又一波的炒作沖昏頭腦,但這些絕佳的機會是以社會和地球為代價的。
缺點包括開採稀有礦物的環境成本、耗時的數據註釋過程的人力成本,以及訓練人工智能模型所需的不斷增長的財務投資,因為它們包含更多參數。
讓我們看一下導致最新一代這些模型並推高相關成本的創新。
大型型號
近年來,人工智能模型變得越來越大,研究人員現在用數千億個參數來測量它們的大小。“參數”是模型中用於根據訓練數據學習模式的內部關係。
對於像 ChatGPT 這樣的大型語言模型 (LLM),借助 Google 的 PaLM 模型,我們將參數數量從 2018 年的 1 億增加到 2023 年的 5000 億。這種增長背後的理論是,即使在最初沒有訓練過的任務上,具有更多參數的模型也應該具有更好的性能,儘管這一假設尚未得到證實。
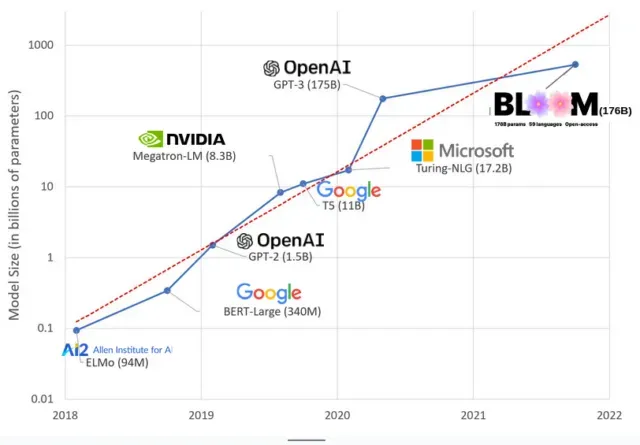
大型模型通常需要更長的時間來訓練,這意味著它們還需要更多的 GPU,這會花費更多的錢,因此只有少數組織可以訓練它們。訓練擁有 1750 億個參數的 GPT-3 的成本估計為 460 萬美元,這對於大多數公司和組織來說是遙不可及的。(值得注意的是,在某些情況下,訓練模型的成本會降低,例如 Meta 訓練的最新模型 LLaMA。)
這在人工智能社區中造成了一道數字鴻溝:那些能夠教授最前沿法學碩士的人(主要是北半球的大型科技公司和富有的機構)和那些不能教授最前沿法學碩士的人(非營利組織、初創企業) ,以及任何無法訪問超級計算機的人)。或數百萬雲積分)。建造和部署這些巨頭需要大量的地球資源:用於製造GPU 的稀有金屬、用於冷卻大型數據中心的水、用於保持這些數據中心在全球範圍內24/7 運行的能源……所有這些都經常被忽視,以利於集中精力注意力。關於所得模型的未來潛力。
行星影響
卡內基梅隆大學教授Emma Strubell對LLM 訓練的碳足跡進行的一項研究發現,訓練一個名為BERT 的2019 年模型(只有2.13 億個參數)會排放280 噸碳排放量,大約相當於五輛汽車的排放量。生活。從那時起,模型不斷發展,設備變得更加高效,那麼我們現在在哪裡?
在我最近寫的一篇科學論文中,研究了訓練BLOOM(一個擁有1760 億個參數的語言模型)所造成的碳排放,我們比較了幾個LLM 的能源消耗和隨後的碳排放,這些都是最近幾年出來的。比較的目的是了解不同規模的LLM排放規模以及影響它們的因素。
發佈留言