Генеративний штучний інтелект – це круто, але не забуваймо про людські та екологічні втрати.

За останні кілька місяців у сфері штучного інтелекту спостерігалося швидке зростання, хвиля за хвилею нових моделей, таких як Dall-E та GPT-4, які з’являлися одна за одною. Щотижня обіцяють нові захоплюючі моделі, продукти та інструменти. Легко захопитися хвилями ажіотажу, але ці блискучі можливості коштують суспільству та планеті.
Недоліки включають екологічні витрати на видобуток рідкісних мінералів, людські витрати на трудомісткий процес анотації даних і зростаючі фінансові інвестиції, необхідні для навчання моделей ШІ, оскільки вони включають більше параметрів.
Давайте поглянемо на інновації, які призвели до появи останніх поколінь цих моделей і підвищили пов’язані з ними витрати.
Великі моделі
За останні роки моделі штучного інтелекту стали більшими, і тепер дослідники вимірюють їхній розмір сотнями мільярдів параметрів. «Параметри» — це внутрішні зв’язки, які використовуються в моделях для вивчення шаблонів на основі навчальних даних.
Для великих мовних моделей (LLM), таких як ChatGPT, ми збільшили кількість параметрів зі 100 мільйонів у 2018 році до 500 мільярдів у 2023 році завдяки моделі PaLM від Google. Теорія , що стоїть за цим зростанням, полягає в тому, що моделі з більшою кількістю параметрів повинні мати кращу продуктивність навіть у задачах, над якими вони спочатку не навчалися, хоча ця гіпотеза залишається недоведеною .
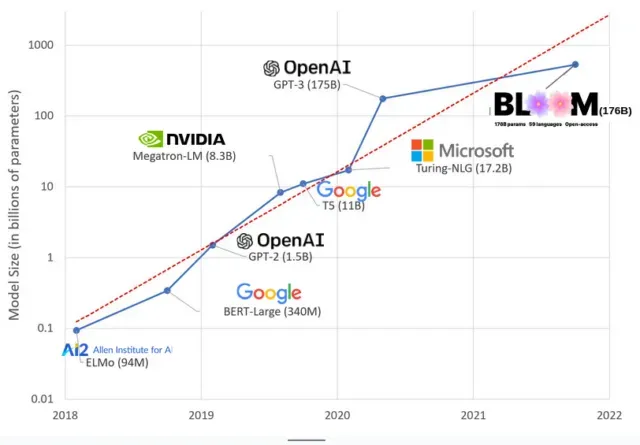
Великі моделі зазвичай потребують більше часу для навчання, що означає, що вони також вимагають більше графічних процесорів, які коштують більше грошей, тому лише кілька обраних організацій можуть їх навчити. Вартість навчання GPT-3, який має 175 мільярдів параметрів, оцінюється в 4,6 мільйона доларів, що є недоступним для більшості компаній і організацій. (Варто зазначити, що в деяких випадках вартість тренувальних моделей знижується , наприклад, у випадку LLaMA, нещодавньої моделі, яку навчає Meta.)
Це створює цифровий розрив у спільноті штучного інтелекту між тими, хто може навчати найсучасніших магістрів права (переважно великі технологічні компанії та заможні установи на Глобальній Півночі), і тими, хто не може (некомерційні організації, стартапи). , і всі, хто не має доступу до суперкомп’ютера). або мільйони хмарних кредитів). Створення та розгортання цих гігантів потребує великої кількості планетарних ресурсів: рідкісні метали для виробництва графічних процесорів, вода для охолодження величезних центрів обробки даних, енергія для підтримання цілодобової роботи центрів обробки даних у планетарному масштабі… на все це часто не звертають уваги на користь зосередженості. уваги. про майбутній потенціал отриманих моделей.
планетарні впливи
Дослідження , проведене професором Університету Карнегі-Меллона Еммою Страбелл про вуглецевий слід підготовки LLM, показало, що навчання за моделлю 2019 року під назвою BERT, яка має лише 213 мільйонів параметрів, викидає 280 метричних тонн викидів вуглецю, що приблизно дорівнює викидам п’яти автомобілів. життя. Відтоді кількість моделей зросла, а обладнання стало ефективнішим, тож де ми зараз?
У недавній науковій статті, яку я написав для вивчення викидів вуглецю, спричинених навчанням BLOOM, мовної моделі зі 176 мільярдами параметрів, ми порівняли споживання енергії та наступні викиди вуглецю кількома LLM, усі з яких вийшли за останні кілька років. Метою порівняння було отримати уявлення про масштаб викидів LLM різних розмірів і про те, що на них впливає.
Залишити відповідь