Twitter publie un code qui, selon lui, détermine les tweets que les gens voient et pourquoi.
Twitter a tenu l’une des nombreuses promesses du PDG Elon Musk en publiant vendredi après-midi ce qu’il prétend être le code de son algorithme de recommandation de tweet sur GitHub .
Le code, publié sous la licence publique générale GNU Affero v3.0 , contient de nombreux détails sur les facteurs qui font qu’un tweet est plus ou moins susceptible d’apparaître dans la chronologie d’un utilisateur.
Dans un article de blog accompagnant la publication du code , l’équipe d’ingénierie de Twitter (sans légende spécifique) note que le système permettant de déterminer quels sont « les tweets les plus populaires qui finissent par apparaître sur la chronologie de votre appareil » « comprend de nombreux services et emplois interconnectés. » Chaque fois que l’écran d’accueil de Twitter est actualisé, Twitter extrait « les 1 500 meilleurs tweets de centaines de millions », indique le message.
La plus grande source de ces tweets sont les « sources en ligne » ou les utilisateurs qui sont suivis par quelqu’un. Les meilleurs tweets de cette pile sont classés en fonction de la probabilité qu’un utilisateur interagisse avec l’auteur de ce tweet ; plus leurs tweets sont susceptibles d’apparaître dans For You. Pour les « sources hors ligne » non suivies par l’utilisateur, Twitter dit qu’il considère les tweets qui attirent l’attention des personnes que l’utilisateur suit et les tweets qui sont aimés par ceux qui aiment les tweets similaires à l’utilisateur.
Déjà ceux qui ont regardé le code ont remarqué des considérations qui soulèvent beaucoup plus de questions. Beaucoup les ont postés, bien sûr, sur Twitter même.
Twitter vient de publier le code source de « l’algorithme ».
Ah c’est quoi ce fichier ? Prédicats pour les tweets sur la chronologie de la maison ?
Oh quelle est cette deuxième image? pic.twitter.com/UE3dU8e3Os
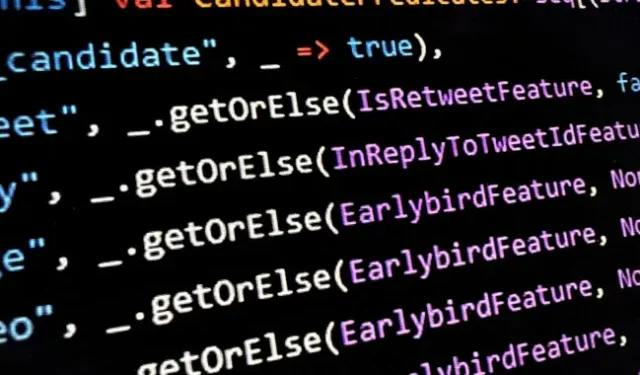
Olafur Vaage, ingénieur logiciel senior au service norvégien de conseil en logiciels TurtleSec, a noté qu’à l’intérieur de « HomeTweetTypePredicates.scala » certaines des considérations possibles pour lesquelles un tweet pourrait être un candidat pour la section « Pour vous » sont les suivantes :
-
author_is_elon -
author_is_power_user -
author_is_democrat -
author_is_republican
Ailleurs dans le code, un commentaire de code prétendument laissé par un ingénieur de Twitter précise que ces valeurs d’identification sont « utilisées uniquement pour collecter des métriques ». Le commentaire va comme ceci:
Ces listes d’identifiants d’auteur sont utilisées uniquement pour collecter des métriques. Nous suivons la fréquence à laquelle nous diffusons les tweets de ces auteurs et la fréquence à laquelle leurs tweets impressionnent les utilisateurs. Cela nous aide à confirmer sur notre plate-forme d’expérimentation A/B que nous ne soumettons pas de modifications ayant un impact négatif sur un groupe par rapport aux autres.
Les noms des objets en question, tels que « DDGStatsDemocratsFeature » ou « DDGStatsElonFeature » semblent soutenir cette interprétation, mais cela peut ne pas être possible de confirmer avec le code disponible. Cependant, il est intéressant que Twitter vérifie et corrèle ces variables. Au cours de la session audio Twitter Spaces, un ingénieur de Twitter a noté que les étiquettes utilisées pour les mesures étaient les démocrates et les républicains. Musk, qui a affirmé qu’il ne connaissait pas les labels jusqu’à aujourd’hui, a suggéré qu’ils ne devraient pas être là.
D’autres éléments pris en compte en relation avec le tweet incluent s’il date de moins de 30 minutes, s’il contient des images et s’il s’agit d’un « utilisateur expérimenté », ce qui, selon certains, signifie un compte vérifié « obsolète « .
Aujourd’hui, la plupart des algorithmes de recommandation seront rendus open source. Le reste suivra.
Le test décisif est que des tiers indépendants doivent être en mesure de déterminer avec une précision raisonnable ce qui est susceptible d’être montré aux utilisateurs.
Nul doute qu’il y aura de nombreux moments gênants… https://t.co/41U4oexIev
Musk a tweeté, avec un article de blog de l’entreprise, que l’algorithme de recommandation, arguant qu’il y aurait un « test acide » si « des tiers indépendants » pouvaient « déterminer avec une précision raisonnable ce qui est susceptible d’être montré aux utilisateurs ».
La publication par Twitter de son code d’algorithme intervient quelques jours seulement après la découverte du code source plus large du réseau social sur GitHub, potentiellement assis là pendant des mois, selon le New York Times . Twitter a ensuite reçu une assignation obligeant GitHub à révéler des informations sur l’affiche GitHub.
Un rapport de Platformer plus tôt cette semaine a déclaré que Twitter avait utilisé une liste secrète des 35 principaux utilisateurs de Twitter, dont le président Biden, LeBron James, Ben Shapiro et Musk. La preuve de la mise en œuvre de cette liste, qui aurait été provoquée en partie par le mécontentement de Musk quant à sa propre implication, n’a pas encore été trouvée dans une base de code publiée sur Twitter.
Plus précisément, le code arrive quelques heures seulement avant que les utilisateurs de «l’héritage vérifié» – ceux qui étaient cochés en bleu pour indiquer l’authenticité ou la notoriété avant que Musk n’achète le service – soient dépréciés au profit des abonnés payants de Twitter Blue. Alors que certains utilisateurs associés à des gouvernements et à de grandes organisations peuvent demander d’autres coches colorées , seuls les abonnés Twitter Blue à 8 $/mois recevront entre autres une « notation prioritaire dans les conversations ».
Tous ces changements ont lieu le 1er avril ou le jour du poisson d’avril.


Laisser un commentaire