За последние несколько месяцев в области искусственного интеллекта наблюдался быстрый рост, и одна за другой появлялись новые модели, такие как Dall-E и GPT-4. Захватывающие новые модели, продукты и инструменты обещают каждую неделю. Легко увлечься волнами шумихи, но эти блестящие возможности дорого обходятся обществу и планете.
Недостатки включают экологические затраты на добычу редких полезных ископаемых, человеческие затраты на трудоемкий процесс аннотирования данных и растущие финансовые вложения, необходимые для обучения моделей ИИ, поскольку они включают больше параметров.
Давайте взглянем на инновации, которые привели к последним поколениям этих моделей и увеличили связанные с ними расходы.
Большие модели
В последние годы модели ИИ стали больше, и теперь исследователи измеряют их размер сотнями миллиардов параметров. «Параметры» — это внутренние отношения, используемые в моделях для изучения шаблонов на основе обучающих данных.
Для больших языковых моделей (LLM), таких как ChatGPT, мы увеличили количество параметров со 100 миллионов в 2018 году до 500 миллиардов в 2023 году благодаря модели Google PaLM. Теория , лежащая в основе этого роста, заключается в том, что модели с большим количеством параметров должны иметь лучшую производительность даже на задачах, на которых они изначально не обучались, хотя эта гипотеза остается недоказанной .
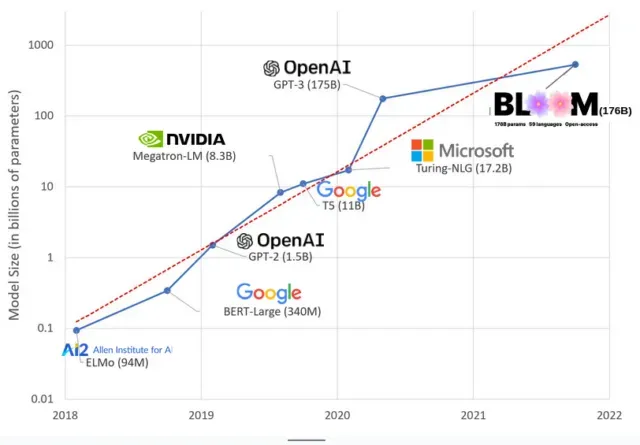
Для обучения больших моделей обычно требуется больше времени, а это означает, что им также требуется больше графических процессоров, которые стоят больше денег, поэтому только несколько избранных организаций могут их обучать. Стоимость обучения GPT-3, имеющего 175 миллиардов параметров, оценивается в 4,6 миллиона долларов, что не по карману большинству компаний и организаций. (Стоит отметить, что стоимость обучения моделей в некоторых случаях снижается , например, в случае LLaMA, недавней модели, обученной Meta.)
Это создает цифровой разрыв в сообществе ИИ между теми, кто может обучать самых передовых LLM (в основном крупные технологические компании и богатые учреждения на Глобальном Севере), и теми, кто не может (некоммерческие организации, стартапы). и всем, у кого нет доступа к суперкомпьютеру). или миллионы в облачных кредитах). Для создания и развертывания этих гигантов требуется много планетарных ресурсов: редкие металлы для производства графических процессоров, вода для охлаждения огромных центров обработки данных, энергия для поддержания этих центров обработки данных в режиме 24/7 в планетарном масштабе… все это часто упускается из виду в пользу сосредоточения внимания. внимание. о будущем потенциале получившихся моделей.
планетарные влияния
Исследование профессора Университета Карнеги-Меллона Эммы Струбелл об углеродном следе обучения LLM показало, что обучение модели 2019 года под названием BERT, которая имеет всего 213 миллионов параметров, выбрасывает 280 метрических тонн углерода, что примерно эквивалентно пяти автомобилям. жизнь. С тех пор модели выросли, а оборудование стало более эффективным, так где же мы сейчас?
В недавней научной статье, которую я написал для изучения выбросов углерода, вызванных обучением BLOOM, языковой модели со 176 миллиардами параметров, мы сравнили потребление энергии и последующие выбросы углерода нескольких LLM, все из которых вышли за последние несколько лет. Целью сравнения было получить представление о масштабах выбросов LLM разных размеров и о том, что на них влияет.